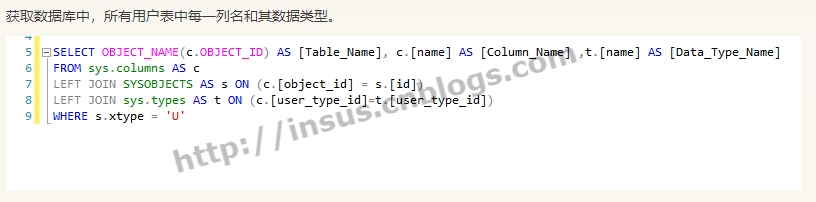
1 创建数据库
create database AA
on
(
name='aa_data',filename='C:\aa.mdf',size=10,filegrowth=5
)
log on
(
name='aa_log', filename='c:\aa.ldf', size=10, filegrowth=5
)
2 备份还原数据库
backup database AA to disk =’E:\aa.dat’
还原数据库
restore database AA from disk =’E:\aa.dat’
3 创建表: create table BB ( … )
创建临时表:#是本地临时表,##是全局临时表
复制表:select * into table1 from table2
约束: 主键 primary key
自增 identity
不能为空字段 not null
默认值 default(1)
外键 id2 int, foreign key (id2) references table1
唯一值 unique
检查 id int check(id>100 and id<200)
4 添加修改删除
insert into 表(字段1,…) values(值1, …)
修改:update 表 set 字段1 = 值1 , 字段2 = 值2 where 主键字段 = 值
删除:delete from 表 where 主键字段 = 值
5 查询
排序 order by desc
模糊 like ‘%a%’
联合 union
分组统计 group by
包含 in / not in / exits / not exits
内连接: 列出与连接条件匹配的数据行
select * from 表1 inner join 表2 on 条件
外连接: 查询结果集合中的不仅包含符合连接条件的行,而且还包括左表(左外连接时)、右表(右外连接时)或两个边接表(全外连接)中的所有数据行
select * from 表1 left outer join 表2 on 条件
交叉连接: 交叉连接不带WHERE 子句,它返回被连接的两个表所有数据行的笛卡尔积
select a1, a2 from 表1 CROSS JOIN 表2 ORDER BY a1
嵌套查询: select * from talbe1 where id = (select …. )
6 流程控制
赋值语句:declare @i int set @i=0
条件语句:if 条件为真
begin … end
else
begin … end
循环语句:while 条件为真
begin … end
7 视图
创建单表视图
create view 视图名
as
select * from employees
8 存储过程
create proc 存储过程名
@i int, –输入参数
@j int output –输出参数
as
begin
…
return
end
9 函数
字符串:
字符串长度 len(‘…’)
获取字符串 str(‘…’) ,返回的是char
截取字符串 substring(开始位置,长度)
随机数 Rand()
时间:
添加时间间隔 dateadd(day, 2, getdate())
时间差 datediff(day, 时间1, 时间2)
获取年,月,日 datepart(yy,getdate())
类型转换:
convert(nvarchar(10), 123), cast(124 as nvarchar(10))
自定函数:
create function 函数名称(@i int, @j int) returns int
as
begin
…
return
end
10 游标
declare 游标名称 cursor for select * from 表
open 游标名称
— declare @i int
fetch 游标名称 –或 fetch from 游标 into @i
while @@fetch_status = 0
begin
fetch next from 游标名称
end
close 游标名称
deallocate 游标名称
11 触发器
create trigger 触发器名 on 表名 for insert –或delete
as
begin
–select * from inserted
insert into 相关表
end
12 事务
事务是指一个单元的工作,这些工作要么全做,要么全部不做。作为一个逻辑单元,必须具备四个属性:自动性、一致性、独立性和持久性
begin tran
if @@error>0
rollback tran
commit tran
13 锁
为什么要引入锁
当多个用户同时对数据库的并发操作时会带来以下数据不一致的问题:
◆丢失更新
A,B两个用户读同一数据并进行修改,其中一个用户的修改结果破坏了另一个修改的结果,比如订票系统
◆脏读
A用户修改了数据,随后B用户又读出该数据,但A用户因为某些原因取消了对数据的修改,数据恢复原值,此时B得到的数据就与数据库内的数据产生了不一致
◆不可重复读
A用户读取数据,随后B用户读出该数据并修改,此时A用户再读取数据时发现前后两次的值不一致
并发控制的主要方法是封锁,锁就是在一段时间内禁止用户做某些操作以避免产生数据不一致
从数据库系统的角度来看:分为独占锁(即排它锁),共享锁和更新锁
共享(S)用于不更改或不更新数据的操作(只读操作),如SELECT语句。
排它(X)用于数据修改操作,例如INSERT、UPDATE或DELETE。确保不会同时同一资源进行多重更新。
更新(U)用于可更新的资源中。防止当多个会话在读取、锁定以及随后可能进行的资源更新时发生常见形式的死锁。
HOLDLOCK持有共享锁,直到整个事务完成,应该在被锁对象不需要时立即释放,SERIALIZABLE事务隔离级别
NOLOCK语句执行时不发出共享锁,允许脏读,READUNCOMMITTED事务隔离级别
UPDLOCK强制在读表时使用更新锁而不用共享锁