谷歌趋势:https://trends.google.com/
谷歌购物洞察
全球商机洞察
分析案例
Sofa,lamp,pillow
谷歌自然搜索大数据判断您产品的竞争力,竞争者,季节性热度等特征
按照时间搜索兴趣
按照平台搜索兴趣
按照区域搜索兴趣
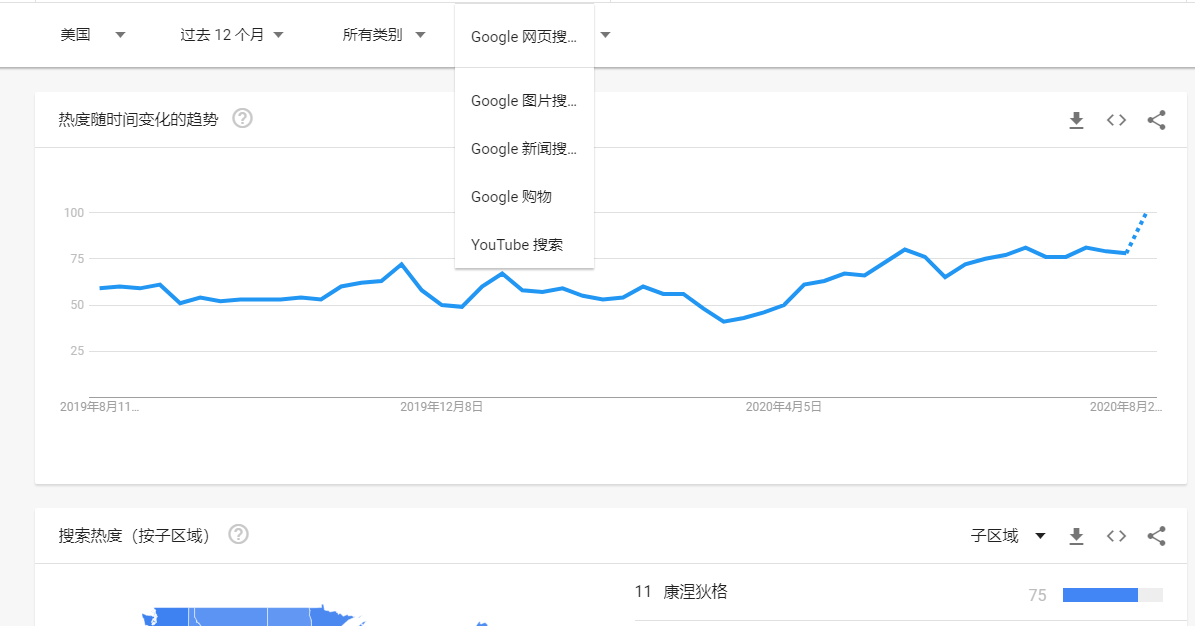
产品热搜词
另外两个工具不怎么用
谷歌趋势:https://trends.google.com/
谷歌购物洞察
全球商机洞察
分析案例
Sofa,lamp,pillow
谷歌自然搜索大数据判断您产品的竞争力,竞争者,季节性热度等特征
按照时间搜索兴趣
按照平台搜索兴趣
按照区域搜索兴趣
产品热搜词
另外两个工具不怎么用
模板结构图
描述:实现分页的一种算法
大致过程:访客访问不同的分页,为这个当前页生成动态的查询SQL,然后送到数据库中执行
输入:总条数,每页多少条,第几页,查询的SQL,排序的字段
注意:传入的排序字段需要构成唯一记录,这就意味着不能单独的使用SortOrder这个单独排序
字段反转:SortOrder asc,PostID desc;反转之后是SortOrder desc,PostID asc;
实现过程
100条数据 每页显示4条 按照ID降序 排序
当取第一页时:直接对所有数据降序取出前4条
当取第二页时:
1.先按降序获得前8条数据,然后升序排列着8条数据,
2.这样第二页的数据直接跑到了前面,取出4条,
3.然后在倒叙回去就是第二页的数据
同样的以此往下类推
当后半数分页时:
当取最后一页时:将所有数据升序过来,取出前4条即可
观察生成的过程
访问前半数分页
访问后半数分页
单文件下载器
功能描述:用来下载迅雷无法下载的资源,单线程操作
输入:一个http文本,要求每一个链接都是唯一的并且文件名不能重复,如果重复的话,下载之后文件会被覆盖掉
注意事项:要求保证充分的异常处理,保证cmd命令窗口不被退出
事项过程:文件流打开文本,循环读里面的每一行,得到下载地址,得到文件名,得到要保存的文件绝对路径,开始下载
扩展:记录下载失败的链接,并加入速度提示
系统浏览次数
都见过这个东西,实现思路
用户访问某篇文章,将这个ViewCount加上1然后更新到数据库中去
都知道这个功能,访问量大的时候会挂掉数据库,所以上面那种实时更新数据库的方式都被淘汰了
实现思路:浏览次数缓存在系统的静态变量中,然后通过系统的定时器,每隔多长时间更新一次数据库,来解决上一种思路频繁的访问数据库带来的访问压力
所以是静态变量+定时器 这两个技术来解决上面这个问题
实现过程:使用字典类型的数据结构 int int 保存ID和Viewcount的数据
两个方法GetView和SetView 频繁的对这个数据结构做修改【因为是静态的,所以不会有什么阻塞,反正在内存中,你该怎么玩儿就怎么玩儿】
到时间之后,定时器会访问这个数据结构,执行一次事务方式的更新
注意点:记得更新成功之后,你需要重新对字典类型做一次加载,保证浏览次数和数据库的保持一致
难点来了:
如果页面做了静态的html缓存,看看上面这个功能还能用么?
这个时候访客访问的是你的html缓存内容,根本就不会执行你的后台 ViewCout++这个代码,你还能用么?
不行了,哈哈怎么办?听火星人说好像ajax这个东西可以呢,哈哈谁知道呢?骚年去试试吧。火星人给你提供了思路哦!!!
像我这种每天手敲文章的人还有多少,其实也挺快乐的,把自己的思想分享给大家,天天写其实会上瘾的哦
那我得到了多少好处呢?锻炼了自己的思维和写作能力,难道我通过这个赚取了百万的收益也会告诉你吗?哈哈说漏了
总结一下StaticHTML相关的问题
围绕几个点来写
用还是不用?
冲突的存在
放在前面还是后面?
StaticHTML:用来生成html代码的缓存,将请求的html结果直接以二进制的方式保存在一个文件中,当用户下载访问的时候,直接输出这个文件中的信息
输出方式:先输出响应头信息;然后输出响应体信息
适用场景:不变html网站;比如一些cms之类的 会提高响应能力
冲突
网站的一些浏览次数,登录状态,301的跳转都会失效
建议:放在url重写模块的前面,这样StaticHTML会首先拦截系统所有的请求,不用再经过url的重写系统,会极大的提高响应速度
URL重写
重写原理
过程分析
疑惑地方
lookfor app.Request.ApplicationPath 如果有子目录的话 这个地方可能会起到作用,暂时不确定
bool flag = url.IndexOf(‘.’) != -1; 标记,表示如果请求后缀包含“.”的我们才进行重写的执行
主要思路:使用筛选器拦截系统所有的请求,
第一步:去除掉不需要重写的请求
第二步:加载系统的重写配置规则
第三步:循环遍历每条规则,如果匹配使用系统的context.RewritePath函数将拦截的请求,转发到我们指定的ashx处理程序当中去
lookfor 到 sendto
注意地方
如何获得系统所有的请求呢?
使用app.Request.Path 【获取当前请求的虚拟路径】表示所用的来到系统当中的请求,通过识别这个值来断定请求是否转发
使用这个还有一个好处,它不带域名,可以实现二级域名的转发操作
循环判断每条规则
每一个请求到达系统当中,都需要匹配每一条规则,每次切换规则,都需要用正则表达式一个实例对象,一旦匹配成功直接跳出循环,这里是比较好性能的地方
正则注意点
完全匹配 ^$ 注意这两个符号,表示来完全匹配一个请求的虚拟路径,上面提到的Path
301的实现
301用来将非www的链接,重定向到www上面去,注意不仅仅是首页的非www跳转
是全站的跳转,所以这个地方的要求就在于必须在for规则循环判断里面写
实现的关键点是app.Request.Url.AbsoluteUri.ToLower(),识别这个绝对url,如果绝对url里面包含一条规则
http://abc.com|http://www.abc.com
也就是StartsWith http://abc.com 就应用301的函数
总结:URL的重写需要把握以上几个关键点,所以请思考
URL重写本质是什么?就是将一条请求路由到我们想路由的处理程序当中去
URL重写入口点在哪里?app.Request.Path 获得拦截的所有请求
URL重写是怎么识别判断的?通过正则表达式
重写后的参数处理
重写的url如果携带参数? 还是通过app.Request.Path
如何从lockfor中也就是重写的url中分离出请求相关的参数呢?
使用正则表达式的Replace函数,来做参数的分离,这个地方是个关键的地方
扩展1
301转发:系统拦截了所有的请求之后,那就可以对请求做任意的转发
扩展2
实现子目录的重写【思考中。。。】
主要的思路都清楚,但是有些细节的地方还不是特别的清楚
思路编写格式,可以从以下几个方面来描述
思路分析法——一切都是思路
要获得一种思路
先把问题搞清楚
获得一个新思路比什么都重要
一个好的思路比什么都重要
先把需求搞清楚
有时候我不便于把一些东西说出来,比如为什么要这样做,要这样设计?只可意会不可言传吧。遇到这些的我只能表示抱歉了
其实还是和需求有关,你的需求是怎样的?你想要什么样儿?你就怎样设计?这就是是为什么要这样设计的原因
实现:分页下的导航条算法
输入:总页数 ,每页显示条数,第几页,链接,中间页数
输出:一段固定的html代码,然后配合Css样式实现分页的效果
规则:
分析过程
将整个分页条拆分出几个部分来组成
上一页
下一页
首页
最后一页
总条数
中间页面
这六个部分组成 其中首页和最后一页都是固定的
实现过程
第一步:
计算出总页数
总页数对每页显示条数求整运算,然后在做求余运算,余数大于0
就要在求整的结果上加上1
就得到总页数了
第二步:
每个步骤的链接
首页的链接是1,ReplaceStr(linkUrl, “id”, “1”)
最后一页的ID是总页数
上一页的链接是 当前页减去1
下一页的链接是 当前页加上1
第三步:
何时禁用按钮呢?
当当前页==1是 上一页禁用
当当期页==总页数是下一页禁用
难点在中间页码该如何计算处理
最后使用全局变量 逐个追加各个变量
扩展:
增加下拉框功能
增加快速跳转到多少页功能
分页条具有多种格式
比如
只显示上一页下一页,不展示中间页码【访客不知道我们网站到底有多少条数据】